My answers to the survey What do you consider to be the main "Big Ideas" in mathematics?
It's all about proofs:
- truth != proof (Goedel's Incompleteness theorems and what follow)
- logic and math still support each other (Reverse Mathematics)
- proofs are not just algebraic manipulation. They give meaning (Combinatorial proofs)
- automation in proof assistants will accelerate mathematical progress by humans (automated deduction)
- the most abstract of abstract nonsense (Category theory, no this not particularly about proofs)
These are all the biggest of big ideas in mathematics. All the others that are specific to an area are what I would consider too... contingent. Topology, algebraic geometry, algebraic K-theory, as important as they are, don't have any far reaching ideas. OK, number three above, combinatorial proofs, I just like a lot and is somewhat like those three I just disparaged.
Wednesday, November 25, 2015
Tuesday, November 17, 2015
Abused dataviz: periodic table and subway map
In addition to wordles, here are two more often abused data visualizations, the periodic table and the subway map.
Both diagram methods are intended to show that among a set of entities, there are many subsets, for the most part mutually exclusive but they have informative intersections. Think of the Venn diagram as the canonical diagram of subset relations. A subway map should have very few intersections (only a handful of entities are in more than one subset, the interchanges or transfer stations). The periodic table has a lot more structure, in fact, as a special case two-dimensional table, the full set can be split into mutually exclusive subsets in two distinct ways.
Take for example the original periodic table.

(from Science Notes)
What a great invention. Mendeleev compiled a bunch of disparate facts, similarities of elements, into a single visualization. The dataviz wasn't perfect, because there were gaps. But the picture was almost a theory, an extrapolation from data, that by 'testing' (further exploration) was confirmed by elements that fit nicely in those gaps. There have been attempts at organizing that chemical information in different ways but Mendeleev's holds primacy.
Nowadays, a periodic table is used for organizing a large set of items that have some similarities. Except the similarities have only tenuous systematic patterns. The point to the chemical table is that they fit nicely into rows and columns according to number of shells and number of electrons in outer shells (which predicts chemical properties nicely). The modern use of these periodic tables seem not to care what patterns in reality there are, just that pretty colors and list. Often the items in a column are not really related, and often they don't go from simple to weighty.

(from Expand via pinterest http://www.xpand.com.au/ )
In this example, the table is simply chart junk. The colors specify the mutually exclusive subsets but the rows and columns say absolutely nothing about the entities.

The periodic table of dataviz has some attempt at using the structure appropriately in the far left and far right columns, but in between its a mess. The site is great for examples, I'm only criticizing the use of the periodic table as the viz method. Note that almost all periodic table viz's use lockstep the funny unbalanced form of the table rather than fit it to the data (the properties of the entities). Instead the entities are shoehorned usually without any reason at all.
The point to a periodic table is that everything in a row should somehow be similar, and everything in a column should also somehow be similar. Also there should be some kind of progression from simple to complex down a column.
When is it appropriate to have a periodic table? When your set of items has two clear dimensions. There can be lots of gaps, or more in one position than another. But the two dimensions need to be clear. Also use those labels! Make sure everything in a column needs to be related. The rows don't necessarily have to be exactly related but at least of roughly the same complexity.
---

Subway maps are diagrams of connectivity of train systems. As a dataviz, they show that certain sets have a handful of points of intersection. Within a subset (shown by a line or track in the system) all the items are related. So when two lines intersect, that item must be a member of both subsets. Unfortunately, many 'subway' maps don't even bother with convention. They'll group items on a line that are only tenuously related, and then a 'transfer point' (an entity on two or more lines) ends up having little to do with either.
What makes a 'subway' map good is when the subsets have very few common entities. That will translate to only a few interchanges, making the diagram easier to create and less busy. It's a plus if you can order the entities along a line in a meaningful fashion (there is some inherent ordering).
Most uses of the 'subway map' dataviz, just like with the periodic table viz, either take a literal subway map (London's usually for obvious for obvious dataviz design homage) and shoehorn entities in, or make up their own but don't bother to make the lines and interchanges act like sets and intersections.

(from Becoming a data scientist) Using some domain knowledge, the items on each colored line aren't very coherent subsets, and their interchanges aren't really common between the two intersecting lines. There is quite a bit of overlap among these entities, lots of subset relations and intersections, but they are unfortunately not even bothered with.
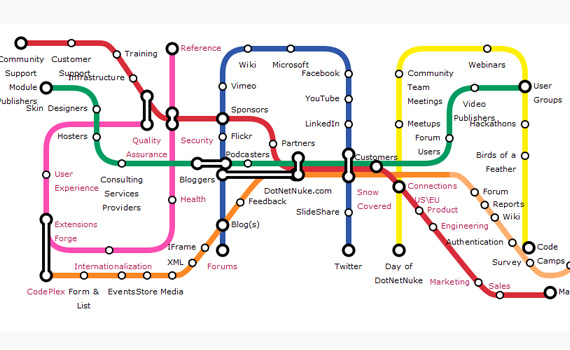
A subway map viz is appropriate for a set of entities if those entities separate nicely into mutually exclusive subsets, with a handful of single entity intersections. If there are many intersections, then there are many constraints on how the lines meet each other.
Consider each entity as as having a list of features. If all the entities have a single feature that partitions the set (these are the subway lines) with very few entities with more than one line (the transfers) then the subway map is appropriate. If all the entities have two features, each partitioning the set in two distinct ways, then a periodic table is appropriate.
These dataviz strategies may well be meaningless chart junk simply to display a list with some structure. They are certainly esthetically pleasing (just like wordles!), but for the most part used irrelevantly. Most lists of entities are easily separated into sublists, with little extra structure, r quite a lot of complicated structure. The subway viz is good is there is a very little bit of common properties. The periodic table is good if there are two mostly coherent discrete dimensions, they don't have to be numbers.
The primary complaint is that the template is ostensibly knowledge based (scientific looking, 'sciency') but that the data poured into them just doesn't have that structure; the structure is a red herring. The dataviz should add something, should give you knowledge about the entities. If the items are on the same subway line, they should have some commonality. An entity in a periodic table should be similar somehow to the other entities in the same column and also the same row.
The alternative, when there is not enough structure, is a simple set of lists. If there is too much structure (lots of common features with little discernible pattern) is to use a venn diagram which captures all the possible intersections.
Or maybe I'm just complaining about incoherent sets and it's not even at the level of the top level structure being a red herring. It's a red herring that it's a red herring.
Both diagram methods are intended to show that among a set of entities, there are many subsets, for the most part mutually exclusive but they have informative intersections. Think of the Venn diagram as the canonical diagram of subset relations. A subway map should have very few intersections (only a handful of entities are in more than one subset, the interchanges or transfer stations). The periodic table has a lot more structure, in fact, as a special case two-dimensional table, the full set can be split into mutually exclusive subsets in two distinct ways.
Take for example the original periodic table.

What a great invention. Mendeleev compiled a bunch of disparate facts, similarities of elements, into a single visualization. The dataviz wasn't perfect, because there were gaps. But the picture was almost a theory, an extrapolation from data, that by 'testing' (further exploration) was confirmed by elements that fit nicely in those gaps. There have been attempts at organizing that chemical information in different ways but Mendeleev's holds primacy.
Nowadays, a periodic table is used for organizing a large set of items that have some similarities. Except the similarities have only tenuous systematic patterns. The point to the chemical table is that they fit nicely into rows and columns according to number of shells and number of electrons in outer shells (which predicts chemical properties nicely). The modern use of these periodic tables seem not to care what patterns in reality there are, just that pretty colors and list. Often the items in a column are not really related, and often they don't go from simple to weighty.

In this example, the table is simply chart junk. The colors specify the mutually exclusive subsets but the rows and columns say absolutely nothing about the entities.

The periodic table of dataviz has some attempt at using the structure appropriately in the far left and far right columns, but in between its a mess. The site is great for examples, I'm only criticizing the use of the periodic table as the viz method. Note that almost all periodic table viz's use lockstep the funny unbalanced form of the table rather than fit it to the data (the properties of the entities). Instead the entities are shoehorned usually without any reason at all.
The point to a periodic table is that everything in a row should somehow be similar, and everything in a column should also somehow be similar. Also there should be some kind of progression from simple to complex down a column.
When is it appropriate to have a periodic table? When your set of items has two clear dimensions. There can be lots of gaps, or more in one position than another. But the two dimensions need to be clear. Also use those labels! Make sure everything in a column needs to be related. The rows don't necessarily have to be exactly related but at least of roughly the same complexity.
---

Subway maps are diagrams of connectivity of train systems. As a dataviz, they show that certain sets have a handful of points of intersection. Within a subset (shown by a line or track in the system) all the items are related. So when two lines intersect, that item must be a member of both subsets. Unfortunately, many 'subway' maps don't even bother with convention. They'll group items on a line that are only tenuously related, and then a 'transfer point' (an entity on two or more lines) ends up having little to do with either.
What makes a 'subway' map good is when the subsets have very few common entities. That will translate to only a few interchanges, making the diagram easier to create and less busy. It's a plus if you can order the entities along a line in a meaningful fashion (there is some inherent ordering).
Most uses of the 'subway map' dataviz, just like with the periodic table viz, either take a literal subway map (London's usually for obvious for obvious dataviz design homage) and shoehorn entities in, or make up their own but don't bother to make the lines and interchanges act like sets and intersections.

(from Becoming a data scientist) Using some domain knowledge, the items on each colored line aren't very coherent subsets, and their interchanges aren't really common between the two intersecting lines. There is quite a bit of overlap among these entities, lots of subset relations and intersections, but they are unfortunately not even bothered with.

A subway map viz is appropriate for a set of entities if those entities separate nicely into mutually exclusive subsets, with a handful of single entity intersections. If there are many intersections, then there are many constraints on how the lines meet each other.
Consider each entity as as having a list of features. If all the entities have a single feature that partitions the set (these are the subway lines) with very few entities with more than one line (the transfers) then the subway map is appropriate. If all the entities have two features, each partitioning the set in two distinct ways, then a periodic table is appropriate.
These dataviz strategies may well be meaningless chart junk simply to display a list with some structure. They are certainly esthetically pleasing (just like wordles!), but for the most part used irrelevantly. Most lists of entities are easily separated into sublists, with little extra structure, r quite a lot of complicated structure. The subway viz is good is there is a very little bit of common properties. The periodic table is good if there are two mostly coherent discrete dimensions, they don't have to be numbers.
The primary complaint is that the template is ostensibly knowledge based (scientific looking, 'sciency') but that the data poured into them just doesn't have that structure; the structure is a red herring. The dataviz should add something, should give you knowledge about the entities. If the items are on the same subway line, they should have some commonality. An entity in a periodic table should be similar somehow to the other entities in the same column and also the same row.
The alternative, when there is not enough structure, is a simple set of lists. If there is too much structure (lots of common features with little discernible pattern) is to use a venn diagram which captures all the possible intersections.
Or maybe I'm just complaining about incoherent sets and it's not even at the level of the top level structure being a red herring. It's a red herring that it's a red herring.
Sunday, November 15, 2015
In defense of publication bias and p-hacking
Publication bias and p-hacking have recently come under a few attacks even though it's not a new thing... not new ... at all.

Publication bias is the tendency to publish study results that have p-value (the statistical measure of 'significance') if the p-value is <= .05 (5%), the magical oversimplifying cutoff stated originally by Fisher as a.. well... magical oversimplification because he found that most people didn't really understand 'really' what p-values mean so he gave this as a quick heuristic for significance.
'P-hacking' is the tendency for researchers to massage the data, the experimental design, the statistical method to improve the p-value output just over the threshold to 'significance' mostly to get around the publication bias.
These are problematic for different reasons. Publication bias leads the literature to ignore the non-information or weak information or non-results, things like 'X doesn't predict Y very well', or 'Treatment Z really doesn't really do much'. These are things that would be nice to know, so a researcher in a field can then either avoid studying such unimportant things or discover refinements of the data that do show something important.
'P-hacking' is a bit more pernicious because it can lead in the direction of outright fabrication. Fixing poorly recorded data removing an outlier (somewhat reasonable, but it is controversial), but this is almost in the direction of fabricating data itself.
Given these well attested problems with publication bias and p-hacking, something about them is actually not so bad, in fact, they are an outcome of very reasonable and desirable scientific behaviors. This is not a justification for 'a road to hell is paved with good intentions', rather that some part of both is actually a good thing.
First, what is bad about publication bias (tending to publish only positive results)? From a literal, rational viewpoint, it is obviously denying half the story, creating all the false negatives. You should report all your results positive and negative to get a good picture. But that is a false equivalence. Positive results are not positive instances of a coin flip. Positive results are the interesting results. Interesting is something new and compelling. The null hypothesis is dull and lifeless. We already knew the null hypothesis. The null hypothesis is the air we walk through constantly. Reporting positive results is like pointing out a new pathway in the forest. Experts in the field, especially editors of academic journals, se many many results on slightly different phenomena. They have a good sense of what is new and important, and what has been done over and over again (and is maybe replication), but they also have a sense of what isn't important or isn't positive in the field. I'm not saying that negative results should not be published, but I do say that they don't need the boosting that positive ones do. A negative result is usually not that interesting. (In the natural sciences, that is; in more mathematical sciences, they are a different sort of thing, and often earth shattering)
And for p-hacking, sure, it is gaming the system. Hacking and gaming are things you do to improve something that are, let's say, hors du combat, outside the system Once you take a measurement, it is something to be gamed. Two runners competing for the fastest time? Train harder, eat better, lean at the tape, starting blocks, better shoes, bend the rules, shave your hair, make up new rules, take meds, get surgery, make up rules about these rules. The difficulty with experimentation and science is knowing what is cheating and what is allowable. For p-hacking, there are rules, things to do, things that are encouraged, things to avoid, and things you just can't do.
P-values are a third order measurement. First, data is the most primary measurement, a stopwatch, a rule, whatever. A statistic (like an average) is a measurement on data, you take a bunch of data and measure that set of data. For the mean, it gives you an idea of the center of the data. Then you can measure the p-value which is a measurement of how reliable the statistic is. At each stage of measurement, gaming can take place. You can manipulate data (remove outliers, 'fix' values) or manipulate the statistic (choose another, sample differently), manipulate the p-value (pick the best one, correct for multiple comparisons) and at each stage of gaming you can do it legitimately or not (no bias or much bias; yes, what the bias is is well underspecified).
The p-value itself is a time honored quantity associated with statistics. It is notoriously subtle and notoriously difficult to teach those subtleties. But it is a very useful measure of quality. It shouldn't be thrown away, just used carefully. When you mix dangerous chemicals, you do it under a fume hood, wear goggles, and have first aid nearby. When you calculate p-values, you make sure you don't calculate many on the same data and pick the best one.
Sure, sure, sure, publication bias and p-hacking are, as stated in that manner with their expected tendentious meanings, to be avoided as such. But the scientific process that results in those things, are not entirely evil. They are natural drives for knowledge and expression of knowledge and convincing people of knowledge. By saying 'natural' I'm not being lenient. Those drives have a correct part and an incorrect part. The part that we label bias and hacking are essentially bad, but the other part is not and is good. Not everything is bad about them.
Wednesday, November 11, 2015
Progress in making Star Trek tech real
There's been a lot of cool sci-fi technology over the years in Star Trek: transporters, phasers, faster-than-light travel. And by sci-fi I mean 'convenient but impossible stuff that helped get the plot move a long'. Star Trek TOS introduced a number of things, NG a few more, the movies I can't think of anything more than "an excess of chronotron particles has created an anomalous rift in the space-time continuum".
But it's kind of funny - since the original series, engineers have almost taken these sci-fi things as a challenge. "Star Trek can do it in the 23rd century. I will make it happen now!". Some things have actually happened; some have been found to be physically impossible. And all sorts between.
Here is an inventory of these plot devices/technologies and 'our' progress (star date spring 2015, 50 years after TOS).
But it's kind of funny - since the original series, engineers have almost taken these sci-fi things as a challenge. "Star Trek can do it in the 23rd century. I will make it happen now!". Some things have actually happened; some have been found to be physically impossible. And all sorts between.
Here is an inventory of these plot devices/technologies and 'our' progress (star date spring 2015, 50 years after TOS).
- transporter - (from The Guardian). It (presumably) records all the positions and velocities of all particles in an abject, and recreates them ... elsewhere. This is theoretically possible and experimentally shown to work on individual electrons. But it needs a lot of work to scale this up to safely transfer humans. It just seems computationally infeasible and would take inordinate amounts of energy to make sure that all the atomic particles get transferred to just the right place. Some scenarios of this require that you have to kill your own doppelganger (it's really just a duplication device). Also, there are myriad niggling details like accounting for the relative speeds of the source and target locations (planets and satellites spinning around at huge velocities). However, one of the side benefits of transporter technology is that it allows you to remove infectious diseases and compute your genome, which, if the quantum relocation problems are solved, would surely be a piece of cake to do. But might allow mishaps aplenty as in many Startrek subplots, and other movies like The Fly. Not impossible, but very difficult with today's technology and economics. There are claims that transporting of objects has been done (see The Guardian article), but I consider that cheating of a form that just isn't cricket.That's a form of manufacturing (which may suffice for the entry on replicators).

- automatic door opening - https://www.youtube.com/watch?v=6CSmkym-Stw This is old news. Every grocery store has had these for years. Either through motion sensors, RFID chips, or weight pads
- artificial gravity - this is a difficult one. What does it mean to have this technology? Without a large mass, can you simulate attraction to a flat surface? Or does a spinning cylinder which mimics gravity count (you'll be able to walk mostly normally, but water will still form messy blobs instead of pouring straight down)? The latter gets a lot, but the former...I don't think there is any physics that says this is at all possible. There's no graviton generator.
However, one can cheat reasonably here. You can 'simulate' gravity on a surface as long as you make the surface accelerate towards the thing you want to exhibit gravity against. Make you spaceship accelerate towards a destination at 32 ft/sec/sec and It feels just like Earth! (turn around halfway and slow down at the same rate, because deceleration is just acceleration in the other direction. Note that this requires lots of fuel, fuel the whole way, rather than just coasting.
Or the old fashioned spinning cylinder would work (with a large enough cylinder), going around a circle is acceleration, too.
Neither of these is cheating, those are real equivalents of gravity. But if what you want is localized gravity, say over a square yard, as different from the adjacent square yard, then no, that's not going to happen.
Progress score: by thinking of gravity as acceleration then yes in some contexts. But, arbitrarily, no, physically impossible.
- invisible force fields or shields (for protection in battle) - same thing. This is actual magic. In that science is not involved. OK, this might be cheatable with lots of magnets. Progress score: never
- cloaking device - The ability to make yourself invisible. Or maybe they've rethought what it means into a solvable formation. Yes, there is technological progress on this, wrapping light to go around an object, or camera on one side projecting to the other. Progress score: sometimes totally yes, other times in progress.
- tractor beam - If there were arbitrary artificial gravity, it could be slightly modified to produce a tractor beam. Except I've heard of laser/magnet/ultrasound pincers for very small scale manipulation in air of particles (like dust). Progress score: not at all. Cheating: maybe
- phasor (weapon for stun or kill) - sorta, not really. Like solar energy, there is the basic technology there, but it just hasn't progressed well. There are 'energy beams' but they take a lot of energy to produce, which is probably too difficult to engineer down to a handheld. But what about those green pointer lasers? I guess making you close your eyes is something. Progress score: sort of, very slow
- photon torpedo - I don't know what's inside that thing. But we have had bad enough destructive bombs since before Star Trek came out. Progress score: already done, but maybe it doesn't glow or have flashing lights on it as it approaches its target, probably for good reason.
- faster than light travel - This is obviously theoretically impossible, even for information, forget objects, All that wormhole stuff is nonsense (at least wormholes that allow an entire ship to travel through unscathed). Dude, if you go into a black hole, you'll be ripped apart before you even get to the event horizon. Of course there may be some cheating thing (transporters?) Progress score: never
- computer disks -
 ( from filmjunk) quickly surpassed and obsoleted. I love this one as an example because it was one of the mini minor details in the TV shows that really made it great. Instead of big file folders of paper. "Just a small piece of plastic? Wow, the future is crazee!." That was the 60's. Then with PCs in the late 70's/early eighties, the floppy disk could be used as a replacement for paper. and it slowly got smaller until the early nineties the 3.5 in disk was widely used and pretty much identical in function to the ST disk. By the mid 2000's, we have thumb drives, barely noticeable on your keychain. And now people keep everything in the cloud. We don't even need a physical device to keep our files, it's just there in the ether. ST had the idea, people created it, people surpassed it, no one uses physical devices anymore.
( from filmjunk) quickly surpassed and obsoleted. I love this one as an example because it was one of the mini minor details in the TV shows that really made it great. Instead of big file folders of paper. "Just a small piece of plastic? Wow, the future is crazee!." That was the 60's. Then with PCs in the late 70's/early eighties, the floppy disk could be used as a replacement for paper. and it slowly got smaller until the early nineties the 3.5 in disk was widely used and pretty much identical in function to the ST disk. By the mid 2000's, we have thumb drives, barely noticeable on your keychain. And now people keep everything in the cloud. We don't even need a physical device to keep our files, it's just there in the ether. ST had the idea, people created it, people surpassed it, no one uses physical devices anymore.

- communicator - Cellphones were invented in the '80s and have improved ever since, even better with apps (smart phones). I guess there are some limitations like we can't talk to the ISS from the ground with our phones (maybe someone at NASA can?) Wait.. we can tweet to the ISS on our phones. Progress score: Done.
- talking computer - yes, to great extent. It's not perfect.It doesn't do all languages automatically. But for European languages, it gets syntax and word choice mostly right (except for a few dings). Slow but steady progress by scientists over the years have created this (despite the bravado of the earliest years of AI claiming it could be done in a couple of years)
- tricorder (handheld noninvasive medical analysis) - not yet, but getting there. There are all sorts of tools now for blood sugar, blood oxigen, temp, etc. Also, radiology is slowly miniaturizing. Next hurdle, hand held DNA sequencer?
- universal translator - crazy impossible AI in the 60's. Hardwon but infinitesimally incremental progress over the years has recently resulted in a passable intermediate stage by Google. Kind of the same explanation as Siri. It's not the best but it's workable if you don't talk too fast.
- DNA analysis - I mentioned the genome when I discussed the transporter and tricorder. Currently, if you have the locations of all the atoms in your body) presumably one can then go through some process on that data to get your DNA sequenced. But without (which the tech to produce the transporter would allow) genome can be done by a big machine for <$1K, but analysis and miniaturization not yet.
- time travel - OK everybody, just shut up. Time travel is not possible at all. At least not in any way like in popular fiction. Wait, I'm sorry, Planet of the Apes got it perfectly right. You can travel into the future (we're already doing that right now, right?), but faster than normal. That is, if you travel at a non-trivial percentage of the speed of light, your time will be slower than others, and when you come back, everybody will have aged more than you. Other people will think you popped in from the past. That's about the extent that physics allows time travel. That's it. No going back in time (we'd have noticed people doing it already), and if you could you couldn't do anything that hasn't happened already. It's all just a plot device that appeals to successful primate brains. When the rodents take over (look at their hands!) and start telling stories, they'll come up with it too.
- replicator - not really, but minimal progress. I consider 3D printing to be one part of this for which there has been great progress (and still more to go). The 3DP will create the physical substrate for an object (the parenchyma if you will). The missing part is the chemical or substance part. If you want to replicate a ham sandwich, you can (could, with some work) 3DP the shape and consistency of the bread, tomato, lettuce, ham, and mayo. But for each of those you still need the taste. And that will need some chemical engineering that I am not aware of. Subtleties in taste, not everything in the grocery store can be imitated with artificial flavoring. Progress score: early stages of prototyping
- holodek - we're almost there. In the 90's there were rooms called 'The Cave' where your environment was displayed on the walls, and you held onto a control device that noted your orientation and movement. It was neat. On the way but not the best. The gaming community has created very life like images and environments. If you call it virtual reality there are VR helmets now. Not totally VR, not total immersion, but even closer. Basically what is needed is better plots and virtual acting.
Did I forget some glaring ones? Sure, the communicator. We've done it. Next.
And surely there are a lot of technologies mentioned before and after, not in ST, that are worthy of discussion. But this is about ST.
For many of these, where I say no or impossible, I'm pretty much challenging you to go around it, by rethinking the rules or outright cheating. That's how engineering works. To get from A to B better than a horse or bird is not to add more legs or implement wings. So maybe you can make a levitating car (but why?) as long as you have a track or ferromagnetic surface.
And surely there are a lot of technologies mentioned before and after, not in ST, that are worthy of discussion. But this is about ST.
For many of these, where I say no or impossible, I'm pretty much challenging you to go around it, by rethinking the rules or outright cheating. That's how engineering works. To get from A to B better than a horse or bird is not to add more legs or implement wings. So maybe you can make a levitating car (but why?) as long as you have a track or ferromagnetic surface.
Monday, November 2, 2015
Language to ask about language while learning
What if you had to learn a new language from scratch as an adult? (because kids just automagically pick it up) and you can't speak English because the other person doesn't know English.
You can always point a finger to get basic nouns, but at some stage (like lesson two) the nouns will get too abstract to point at. You can point at different examples of food but not 'food' itself. Likewise some verbs you can show, "I am running", but they'll get abstract even quicker "I have".
I've collected some phrases that should be a special section of its own in language learning. They are intended to help you bootstrap into a language, if you are so lucky to find yourself in this intermediate scenario.
You really need two kinds of things, a set of bootstrapping utterances that a normal fluent adult (works fine for kids too) speaking the language already would ask if they just forgot something. And then you want a set of things that a normal fluent adult would say as a matter of course, those little in between words, um's and oh's, most likely not in the dictionary.
I don't understand.
I don't understand that word.
I don't know.
I don't think so.
I'm not sure.
I know.
I understand.
What? (I didn't hear you or I didn't understand)
Can you repeat that?
Can you say that slowly?
Can you say that again? Can you repeat that?
Can you explain that? Can you say that a different way?
What is that?
What do you call that?
What does X (a word in the new language) mean?
Is there a word for (some description in the new language)?
How do you say (some description in the new language)?
How do you say 'Y' (a word in your own language, not in the language being learned)? (if you are so lucky to already have someone bilingual as a teacher)
How do you spell 'X'? (if you are so lucky as to have a common writing system)
Of course.
Not at all, of course not.
Really?
Are you sure?
I can't tell the difference.
Do people really say that? Does everyone say that?
These should be a necessary part of the elementary language curriculum in any language. Also when translated into these other languages (the native language to be learned) they should be translated literally or formally, but have the corresponding way the natives say it.
For whatever language you're learning, find/translate/get these phrases in the new language and they'll speed up your fluency. The idea is to speak with awareness in the other language, to act as a native speaker would in their language. (OK, no native speaker would use many of these because of pragmatic concerns, not wanting to look like you don't understand).
You can always point a finger to get basic nouns, but at some stage (like lesson two) the nouns will get too abstract to point at. You can point at different examples of food but not 'food' itself. Likewise some verbs you can show, "I am running", but they'll get abstract even quicker "I have".
I've collected some phrases that should be a special section of its own in language learning. They are intended to help you bootstrap into a language, if you are so lucky to find yourself in this intermediate scenario.
You really need two kinds of things, a set of bootstrapping utterances that a normal fluent adult (works fine for kids too) speaking the language already would ask if they just forgot something. And then you want a set of things that a normal fluent adult would say as a matter of course, those little in between words, um's and oh's, most likely not in the dictionary.
Bootstrapping words
I don't understand.
I don't understand that word.
I don't know.
I don't think so.
I'm not sure.
I know.
I understand.
What? (I didn't hear you or I didn't understand)
Can you repeat that?
Can you say that slowly?
Can you say that again? Can you repeat that?
Can you explain that? Can you say that a different way?
What is that?
What do you call that?
What does X (a word in the new language) mean?
Is there a word for (some description in the new language)?
How do you say (some description in the new language)?
How do you say 'Y' (a word in your own language, not in the language being learned)? (if you are so lucky to already have someone bilingual as a teacher)
How do you spell 'X'? (if you are so lucky as to have a common writing system)
Of course.
Not at all, of course not.
Really?
Are you sure?
I can't tell the difference.
Do people really say that? Does everyone say that?
These should be a necessary part of the elementary language curriculum in any language. Also when translated into these other languages (the native language to be learned) they should be translated literally or formally, but have the corresponding way the natives say it.
Quasi-language
Quasi-language is utterances that are from the mouth but are not terribly dictionary oriented. To be a native speaker of a language, you should be able to 'say' these kinds of things (translated appropriately of course).
Uhhh, ummm - a 'spacer' between words while you think of what to say next instead of leaving a pregnant pause
Uh-huh, yeah - very informal yes
Unh-unh, nuh-unh, mn-mm - very informal no
Ow - an exclamation of mild pain
Oops - if you dropped something or made a mistake
Tsk-Tsk - registering disapproval
Ah - registering understanding
Oh - registering mild surprise
Hey - to get someone's attention loudly
Shh - to tell someone to be quiet
Uh-huh, yeah - very informal yes
Unh-unh, nuh-unh, mn-mm - very informal no
Ow - an exclamation of mild pain
Oops - if you dropped something or made a mistake
Tsk-Tsk - registering disapproval
Ah - registering understanding
Oh - registering mild surprise
Hey - to get someone's attention loudly
Shh - to tell someone to be quiet
Of course, some of these may be US/AmE particular and you 'just don't say it' in other 'languages'.
Subscribe to:
Comments (Atom)