This could just as well be framed as a taxonomy of magic or magical creatures or comic superpowers; you may disagree with details but the whole structure holds conceptually. There may be no actual facts involved (or maybe there are!), but the concepts are consistent. Also, I take this as a subset of the taxonomy of magic because there's (currently!) no scientific evidence but in the back of our heads we kind of feel like maybe we've experienced it or really really hope that there is some small ability there
First, let's define ESP (extrasensory perception) starting from examples, often being lucky enough that there are single English words that already capture the essence, and abstracting. There's clairvoyance (seeing the future), there's telepathy (perceiving someone's thoughts), mind-control (changing someone's thoughts by your own), speaking with the dead, telekinesis (moving objects with your mind), predicting random cards.
I'm setting an arbitrary boundary so that things we informally think are magical are not included (ghosts, gremlins, witches), that are 'obviously' unscientific and magic tricks (card tricks, optical illusions), which are intentionally supposed to seem magical but have a deterministic scientific explanation (astrology (depends supposedly directly on the location of the sun and planets)). These choices of mine are somewhat arbitrary. They could easily be included but then where do we stop (wait what about tarot and palm reading and tea leaves? what about entertainment magic, sleight of hand and actual tricks (ha ha that's hard to say right))
With these examples in mind, we can start to take apart what it means to be ESP and categorize all the kinds. The first thing to notice is that, along with perception, I am including action. So extrasensory perception or action is perceiving or doing things beyond our known senses. So we are well aware of seeing with our eyes and pushing with our hands; ESP is the ability to do those without currently known physiological organs. Presumably the organ will end up being the brain (the seat of thought), but maybe if we find out that we are able to see through the backs of cards using higher frequency receptors in our eyes (a deterministic scientific explanation) then this action will become a nonExtra Sensory Perception (NESP).
This brings up the tangent of making well formed categories. It is usually considered bad practice to have a subcategory, a sibling category, that is 'everything else that is not included'. For example, the category Vehicles could include Cars, Bikes, Planes, and NOS (Not Otherwise Specified). The latter category might cause difficulty because a sailboat will have to change category if a new subcategory of Vehicles, namely Boats, is created. (Note the difference between a category (eg Boats) and instances (sailboat), which of course could be generalized to become a category on its own)
A taxonomy of concepts forms a tree which expects all subtrees to be non-overlapping. Most collections of concepts end up having some overlaps, and this will be pointed out, but non-overlapping is a simplifying assumption that will make things easier to diagram.
- sensing
- 'perceiving' events
- clairvoyance, premonition - seeing events in the future, past, or remotely
- guessing cards
- predicting events
- telepathy - knowing others' thoughts
- mentalism - cold reading
- channeling - communicating with spirits
- seances - speaking with the dead (formerly actual people), knowing the thoughts of someone who has died
- sensing auras - 'seeing' the personality of a person
- out-of-body experience - astral projection
- acting
- telekinesis - or psychokinesis, moving objects
- levitation - raising objects
- oneself - as in extreme yoga
- somebody else
- objects
- making objects disappear
- modifying objects
- bending spoons
- destroying and remaking things (watches, dollar bills)
- pyrokinesis - starting fires (inspired/invented by fiction, Stephen King)
- telepathy - transfer of thoughts, more than just sensing
- sending thoughts, communicating
- putting ideas in someone's head
- mind control
- body control
I've never defined magic or science, only working with them informally. The creation of the relations among these things helps us define our terms, putting things together that go together but avoiding conflicts and inconsistencies by separating differences.
This is an exercise in philosophy and taxonomy. That is, I'm just playing with words and our mental perception of them, mainly because science could be done on these things, and has, but it has just never panned out. So all I have to go on them is what we imagine. So this taxonomy is not (as currently known) about scientific things, but is itself scientific because people have ideas of what these individual concepts could mean and could disagree with the relations I have put among them. Note that I've really only put a subset relation (is-a) and extremely minimal comments.
The only practical argument against any of these abilities being real (or scientific) is that no one has used any of these things for anything other than those particular entertainments. That is, if ESP/magic were repeatable with other objects, we could use, for example, the spoon bending skill for other metals and substances in industrial manufacture. Or we could teach quadriplegics how to do small tasks requiring dexterity. Or communicate without telephones. Of course the counterargument which is not a counterargument is the ability of pickpockets to take personal objects without us knowing. Some 'magic' is possible, just not by the purported skills.
What's interesting about the above taxonomy is that most (serious) people don't really believe that any of these phenomena are real. This is counting angels on a pinhead, building castles in the sky. There is no there there. But we've drawn a perfectly coherent picture. And frankly, it could turn out that some of these are physically realizable, through some sort of deterministic, scientific process.
Saturday, October 31, 2015
Friday, October 30, 2015
Language learners
What's happening with language learning:
- One unknown word ruins a sentence: a single unknown word in a sentence can totally negate any meaning the sentence might otherwise give. If you have never heard a word before, for a native speaker you often have enough context and history to figure the part of speech, how it relates to the other words, who is doing what to whom. But to the non-native learner, it totally throws off everything. All the other words, which you previously know, may now have their meanings in question. And all the intellectual energy you're expending trying to figure out the unknown word is taken away from all the other words, making the known words, still shaky in this new language, even less sure.
Native speaker reaction: "dumbledore must be a grocery store."
Learner reaction: "Did you just call me a ... a bird?"
- A learner is lenient, a native is strict: To a native speaker, there are lots of collections of words that are similar sounding and have similar meaning but are not the same. For example, all the various word forms of a conjugation "has, have, had" or cognates ", To the native speaker, these individual words are all very distinct. Using one instead of another is a glaring error, a discordant note, banging your thumb with a hammer obvious. To the language learner, they're kinda the same. To someone foreign to both, Italian and Spanish are a lot alike, you can sorta make half sense of both about the same. But of course to them they are mutually unintelligible (but can pick out a few words here and there). To the learner everything close is good enough. To the native the slightest hint of a difference is shockingly noticeable, strange, and almost unrecognizable. This works for all areas: pronunciation, syntax, word choice.
Native speaker reaction: "Want? That makes no sense. Did you want something at the grocery store? Did you want a grocery store? I don't get it."
Learner reaction: "Did you get chicken and potato salad?"
- Throw away step ladder: It seems universal in language teaching to start off with extremely simple sentences in the present indicative: "I read", "They eat". In English at least this is hardly ever used in practice. Surely there are short simple sentences that are actually used that can be taught.
What normal people actually say: "I used to go to the movies every Friday."
- Translationese: word for word translation is easy and often a sentence can preserve meaning from one language to the next with a constituent to constituent dictionary translation. But often "that's just not how they say it in X". Frankly in English that's just not they say it (see the throw away step ladder).
What is taught: "That is correct"
Natural: "Of course", "Right", "Yes", "Sure", "I guess so"
- Style is not grammar: lots of rules are given (a consistent single rule to learn is much easier to remember than a more complex one) for which it is actually a style rule or a rule of register (formal vs informal). Also, most language teaching is academic and for a future business or academic use. In most languages (moreso but still a little in English) there is a big difference between the language called X in school and that called X at home. This can lead to a good language learner to be 'better' or excessively more formal than a native speaker.
What people say: "I gotta go t'th'CVS 'n' pick up somethin' real quick"
Basic Pun "Where do polar bears vote?"
Learner: "The North Poll! Ha ha! I get it! Because 'poll' sounds just like 'pole' but they're two different things, one is for ..."
- Humor and sarcasm: anything other than the most literal will not be caught by the language learner. The learner probably has no idea that the same sounds can mean very different things depending on context (forgetting cultural background altogether). On the other hand, when a learner does notice a homophone, they will find it the most hilarious thing in the world but it will barely register with the native speaker.
Lack of humor "Where do polar bears vote?"
Native speaker: "The North Poll!"
Learner: "I don't understand. Can polar bears vote?"
Learner: "I don't understand. Can polar bears vote?"
Basic Pun "Where do polar bears vote?"
Learner: "The North Poll! Ha ha! I get it! Because 'poll' sounds just like 'pole' but they're two different things, one is for ..."
Native speaker: "Groan. Also, polar bears can't vote"
The point is that someone learning a language is using all their mental energy to pick out the right sequence of words, to get the order right, pronunciation, to remember that one weird word, etc etc that it's the most unnatural thing in the word, and they sometimes miss the eventual meaning.
Monday, October 26, 2015
Vapnik says "Deep Learning is the Devil"...maybe
Zach Lipton gave a summary of Vapnik's talk at Second Yandex School of Data Analysis conference (October 5-8, 2015, Berlin). Lipton wrote:
My interpretation of all this is that this is about the difference between science and engineering, or general vs specific. Coming up with a good general algorithm, I'm guessing Vapnik is thinking of SVMs or the idea of neural networks, is the study or science of ML, but most successes of Deep Learning (or really just particular and particularly large neural networks) come from the given design of the DL network.
As to clever vs brute force, somehow the statement that can be extracted is that DL is not clever but devilishly brute force. I'm not sure how to make sense of this (I don't see how DL is more brute force that SVM or logistic regression or random forests). Unless all the work that must be done in engineering a good DL is in creating the topology of nodes; this is not automatic at all but needs a lot of cleverness to make a successful learner. But the DL part enables that cleverness (which would otherwise be impossible).
Cleverness is not easily scalable; you can't just throw a whole bunch of extra nodes and arbitrary connections into a DL and hope it learns connections well, you have to organize the layers well. Those details,, the needed to be clever is what slows down the scaling and I am guessing it what is 'devilish' about DL.
This is all second hand and rewording of suggestions through someone's hearsay, and connecting dots that are barely mentioned and far apart. I'm totally putting words in his mouth, but this is what I expect Vapnik really means (or what I think Lipton thinks that Vapnik thinks, all telegraphically expressed). But really how much of anything is really not that?
Vapnik posited that ideas and intuitions come either from God or from the devil. The difference, he suggested is that God is clever, while the devil is not.and
Vapnik suggested that the devil appeared always in the form of brute force.and
[Vapnik] suggested that the study of machine learning is like trying to build a Stradivarius, while engineering solutions for practical problems was more like being a violinist
My interpretation of all this is that this is about the difference between science and engineering, or general vs specific. Coming up with a good general algorithm, I'm guessing Vapnik is thinking of SVMs or the idea of neural networks, is the study or science of ML, but most successes of Deep Learning (or really just particular and particularly large neural networks) come from the given design of the DL network.
As to clever vs brute force, somehow the statement that can be extracted is that DL is not clever but devilishly brute force. I'm not sure how to make sense of this (I don't see how DL is more brute force that SVM or logistic regression or random forests). Unless all the work that must be done in engineering a good DL is in creating the topology of nodes; this is not automatic at all but needs a lot of cleverness to make a successful learner. But the DL part enables that cleverness (which would otherwise be impossible).
Cleverness is not easily scalable; you can't just throw a whole bunch of extra nodes and arbitrary connections into a DL and hope it learns connections well, you have to organize the layers well. Those details,, the needed to be clever is what slows down the scaling and I am guessing it what is 'devilish' about DL.
This is all second hand and rewording of suggestions through someone's hearsay, and connecting dots that are barely mentioned and far apart. I'm totally putting words in his mouth, but this is what I expect Vapnik really means (or what I think Lipton thinks that Vapnik thinks, all telegraphically expressed). But really how much of anything is really not that?
Friday, October 23, 2015
Best Science Fiction Movies Ever
My list of best science movies ever:
I'm making little distinction between a single great movie in a series and the rest of the series. All of these refer mostly to the first ones in a series. I don't know what it is about Star Trek. The TV shows are way better than the movies; but the movies are somehow terrible (except as everyone agrees ST II: The Wrath of Khan). The modern J.J. Abrams reboots are enjoyable but nothing new and forgettable.
A handful require a mention but just don't make the list: THX-138; A Boy and his Dog; The Andromeda Strain; Stalker; A Clockwork Orange; Sleeper; Galaxy Quest; were all important when I was younger, but not really anymore (well, every other line in Sleeper is memorable).
Most scifi movies are just junk: action-adventure schlock.
The only one I feel bad about not putting on the list above is Wall-E. It's obviously well-done, there are a number of things in it that are memorable and prescient. But all I can say is "sorry animation".
Motivated by the Skeptics Guide to the Galaxy Episode #536 (10/17/2015) their top 5 sci fi movies.
- 2001: A Space Odyssey - the story is superior, the sets and effects still look modern.
- Blade Runner - again, the story is superior, the sets and effects still look modern. The attention to detail is amazing.
- Star Wars - simple minded but so audacious. Too many false notes to be the top
- The Matrix; Terminator - both stories excellent and very distinct but somehow similar. Hard to distinguish quality.
- Jurassic Park - almost too commercial
- Planet of the Apes - kitschy sets and costumes and dialog and acting (after the first one, they are all very amateurish), but rich in sci fi. This is the only one of mine that I think is very questionable. But I think it deserves a lot more credit.
- Road Warrior (and Mad Max I) -
- Brazil; Memento (I know they're not considered scifi, but both belong here for me)
- Too recent to judge reliably: Inception; Minority Report; Gravity; The Martian; District 9; Avatar; Children of Men; Source Code; Edge of Tomorrow; Looper; Predestination; Surrogates; Elysium; Limitless; Interstellar. I really liked all of these but I can't tell if they'll mean much to me later.
- 12/16 Arrival
I'm making little distinction between a single great movie in a series and the rest of the series. All of these refer mostly to the first ones in a series. I don't know what it is about Star Trek. The TV shows are way better than the movies; but the movies are somehow terrible (except as everyone agrees ST II: The Wrath of Khan). The modern J.J. Abrams reboots are enjoyable but nothing new and forgettable.
A handful require a mention but just don't make the list: THX-138; A Boy and his Dog; The Andromeda Strain; Stalker; A Clockwork Orange; Sleeper; Galaxy Quest; were all important when I was younger, but not really anymore (well, every other line in Sleeper is memorable).
I feel like I have to mention The Day the Earth Stood Still; Forbidden Planet; Metropolis only because they're near the top of everyone else's list. But I have to be honest and say they just feel so all around dated.
Most scifi movies are just junk: action-adventure schlock.
I went through a few top 100 lists just to make sure I wasn't leaving any out. If the title is not in this list (and there's lots), sorry, I just didn't think enough of it. If you were to ask me about one not here, I'd probably say, "I suppose it was OK, but it just doesn't fit in my best ever list". For example Tron. I remember being very excited about that as a kid, but, despite its main idea, it's just not that great. Some people think Dune (by David Lynch) was epic, but I feel like they must have seen a different movie (I thought the film was terrible) and their opinion was colored too much by the book. Soylent Green, Westworld, and The Omega Man - these are of the same kitschiness as Planet of the Apes, but only have one note each (also Charlton Heston mostly; is that the problem?).
The only one I feel bad about not putting on the list above is Wall-E. It's obviously well-done, there are a number of things in it that are memorable and prescient. But all I can say is "sorry animation".
At the end all I can say is that this is not opinion, it is objective truth. So if you don't agree, either you're wrong, or I have made a transcription error.
Motivated by the Skeptics Guide to the Galaxy Episode #536 (10/17/2015) their top 5 sci fi movies.
Tuesday, October 20, 2015
Cognitive computing is AI rebranded from the point of view of an app
Artificial Intelligence is whatever it is about computing that is sort of magic. As users we don't know why exactly it works but it just does. As builders it's like the dumbest of magic tricks: fast hands, misdirection, brute force beforehand. Sure a lot of research has gone into clever math for it, but once you look behind the curtain, you realize the excitement of the builder is in fooling the user, passing the Turing test by whatever means necessary. (I exaggerate considerably for effect. There's lots of rocket science behind the curtain, but what distinguishes it from algorithms is that it embraces inexact heuristics rather than shunning them).
AI doesn't have to be electronic. It could be mechanical, like a ball-bearing finite state machine that computes divisibility by three, or biological (like a chicken taught to do tictactoe). The chicken winning is magic. The brute force is determining the tictactoe decision tree then teaching the poor chicken. In the end, AI is mostly just computers.
It is usually something that humans are only able to do: language, vision, and logic.
AI is often used for just a heuristic such as the game 2048. The AI used to try to get a better score is essentially heuristics found by a good human player that were then coded as rules in a deterministic program. When you open the hood, there's no rocket science, it's just "always make a move that keeps the highest item in the corner", a human thought that is better than random and better than a beginner, but not perfect. An airline flight suggester is just (OK it is sorta rocket science) a special linear optimization problem (on a lot of data). Linear optimization is usually not considered AI but let's not quibble.
AI usually means that some learning was involved at some point but usually that learning is not continuous, learning in operation. Probably some ML algorithm was run on a lot of past data to generate a rule and then set in stone (until another pass on more recent data updates the rule).
The short history of AI is that it was invented/named in the late 50's, expected to solve all problems in a couple years in the mid 60's
Cognitive computing is IBM's way of reintroducing AI to consumers. It's not AI, but it's not not AI. That is, it is AI dressed up as usable applications or modules that can be fit together to give the appearance that a human is behind it without having an actual human having to step in to do it. The usual list of properties that a cognitive computing app has are: awareness of context of the user, giving the user what they want before they ask for it, they learn from experience, deals well with ambiguity. But then it will probably also incorporate human language input or visual pattern recognition or thinking through a number of inference steps.
Do you need an app that'll give you a new good tasting recipe for tacos? Deciding what's best is probably a good human task (but shhh we have an ML algorithm that figured out what are good ingredient combinations). Do you need an app that suggests to you good personalized travel plans? And now for something actually practical, do you need an app that will help discover cancer cures from buckets of EHR data?
All of these are not the usual single narrow one-off AI apps (back up a trailer, distinguish cats from dogs in images, compete in rock paper scissor competitions).
Without a doubt, cognitive computing is totally a hype/marketing term, new enough not to be some old over-used baggage-laden term like AI, not misleading (these are all sort of thinking apps) and vague enough to allow all sorts of companies to jump on the bandwagon with "Why yes, we've been doing cognitive computing before the term was invented!"
But hype terms can be useful. Cognitive computing is a good label for engineering a combination of features, some that are traditional AI and some that are just good design that are becoming more obvious to have. Whether it's the machines doing the thinking in silicon, or the engineers doing some extra thinking in design, as long as the machine looks like it's reading your mind then that's a good app. It'll be useful if it catches on.
AI doesn't have to be electronic. It could be mechanical, like a ball-bearing finite state machine that computes divisibility by three, or biological (like a chicken taught to do tictactoe). The chicken winning is magic. The brute force is determining the tictactoe decision tree then teaching the poor chicken. In the end, AI is mostly just computers.
It is usually something that humans are only able to do: language, vision, and logic.
AI is often used for just a heuristic such as the game 2048. The AI used to try to get a better score is essentially heuristics found by a good human player that were then coded as rules in a deterministic program. When you open the hood, there's no rocket science, it's just "always make a move that keeps the highest item in the corner", a human thought that is better than random and better than a beginner, but not perfect. An airline flight suggester is just (OK it is sorta rocket science) a special linear optimization problem (on a lot of data). Linear optimization is usually not considered AI but let's not quibble.
AI usually means that some learning was involved at some point but usually that learning is not continuous, learning in operation. Probably some ML algorithm was run on a lot of past data to generate a rule and then set in stone (until another pass on more recent data updates the rule).
The short history of AI is that it was invented/named in the late 50's, expected to solve all problems in a couple years in the mid 60's
Cognitive computing is IBM's way of reintroducing AI to consumers. It's not AI, but it's not not AI. That is, it is AI dressed up as usable applications or modules that can be fit together to give the appearance that a human is behind it without having an actual human having to step in to do it. The usual list of properties that a cognitive computing app has are: awareness of context of the user, giving the user what they want before they ask for it, they learn from experience, deals well with ambiguity. But then it will probably also incorporate human language input or visual pattern recognition or thinking through a number of inference steps.
Do you need an app that'll give you a new good tasting recipe for tacos? Deciding what's best is probably a good human task (but shhh we have an ML algorithm that figured out what are good ingredient combinations). Do you need an app that suggests to you good personalized travel plans? And now for something actually practical, do you need an app that will help discover cancer cures from buckets of EHR data?
All of these are not the usual single narrow one-off AI apps (back up a trailer, distinguish cats from dogs in images, compete in rock paper scissor competitions).
Without a doubt, cognitive computing is totally a hype/marketing term, new enough not to be some old over-used baggage-laden term like AI, not misleading (these are all sort of thinking apps) and vague enough to allow all sorts of companies to jump on the bandwagon with "Why yes, we've been doing cognitive computing before the term was invented!"
But hype terms can be useful. Cognitive computing is a good label for engineering a combination of features, some that are traditional AI and some that are just good design that are becoming more obvious to have. Whether it's the machines doing the thinking in silicon, or the engineers doing some extra thinking in design, as long as the machine looks like it's reading your mind then that's a good app. It'll be useful if it catches on.
Friday, October 16, 2015
The Long Burning Hype of Hype Indicators
(motivated by From Turing to Watson: The Long-Burning Hype of Machine Learning)
Hype is bullshit. It is not true, but it is also not necessarily false. In fact it has only a tenuous connection to the true/false dichotomy/continuum. It is only exclamation.
It is the hot-or-not score. It is the Time magazine weekly up or down cultural indicator. It is based on empty anecdotal perception, vaguely perceived frequency of mention or frequency of thought or coolness or I don't know what.
It is barely a measure of anything other than the .
The Gartner Hype Curve is also hype. It attempts to inform about the hype stage of many closely related items at once. But it turns out that is a piece of hype itself. The hype cycle is a well-hyped pseudo-scientific (non-evidenced based) proof-by-look-there's-a-picture.
Here is the general pattern:

It is very compelling. I have to be honest and say that that's exactly the timeline of how I think of things. At first I've just never heard of the thing. Then one mention.Then three in one day, then I hear and think of it all the time, then I get just sick of it, nauseated at the thought. Then it comes back as an accept everyday thing. Here's an example of a set of items from the
But... really? That's just a made up story. It seems to match what I think of as a story of popularity. It seems to match a good Hollywood drama: hero has early success and downfall and then third act of redemption.
And it is just the vaguist notion of mood swings. And also what is the point besides entertainment, or schadenfreude or rooting for a comeback?
Look at the following. So sciency. Look at all the data points that you can follow year after year (the data viz is a bit hard to read the course of any particular item, but that's a minor quibble in comparison to the the central problems).

The hype curve might be a useful thing, if only it measured something that is 1) coherent and 2) based on evidence. Introspection is a great inspiration but it is not measurable.
What is the meaning behind the graph? Also whatever the meaning what is the data underlying the graph?
The easy answer is the source of the data. It is simply the 'educated' guess of Gartner analysts. Not an actual number.
Take any particular item. Does it follow the curve? Does it match the icon? Each label is a hype term, but has its own definitional problems. Each term can be vague, have multiple meanings, and have multiple incommensurate sources.
Note also that the shape and timing of the graph is the same for all items. The different point icons are the only appeal to different scales for each item.
So time, the x-axis, is incoherent (unmentioned context based for every item). Different thing might move along the supposed curve at different rates.
But what about the y-axis? Is it popularity, that is, how often an item is mentioned (mentioned in tweets or on google)? or is it how successful an 'item' is (let's say quantitatively, money, earnings per year?) Even these ostensibly measurable concepts are problematic because of definition of terms (is one label the same or different than another).
And once you nail down what the measurement should be, Gartner isn't doing any kind of such measurement, and there's no guarantee that the hype curve shape is a common pattern. It may be that an item's curve is up then down (then dead). Or it may have a steady rise. Or it may have multiple hype peaks at different scales. Or frankly it may have a curve like any stock, up down, steady, with most any pattern imaginable.
If you want to make the hype curve useful. Pick a meaning (or meanings, heck go wild and have many types of hype) and then actually measure it. And only then will people... wel they won't accept that unconditionally, they'll also complain about the coherence of the concept measured and measuring difficulties. But at least it will be scientific evidenced based hype rather than just empty celebrity bullshit hype.
Hype is bullshit. It is not true, but it is also not necessarily false. In fact it has only a tenuous connection to the true/false dichotomy/continuum. It is only exclamation.
It is the hot-or-not score. It is the Time magazine weekly up or down cultural indicator. It is based on empty anecdotal perception, vaguely perceived frequency of mention or frequency of thought or coolness or I don't know what.
It is barely a measure of anything other than the .
The Gartner Hype Curve is also hype. It attempts to inform about the hype stage of many closely related items at once. But it turns out that is a piece of hype itself. The hype cycle is a well-hyped pseudo-scientific (non-evidenced based) proof-by-look-there's-a-picture.
Here is the general pattern:
It is very compelling. I have to be honest and say that that's exactly the timeline of how I think of things. At first I've just never heard of the thing. Then one mention.Then three in one day, then I hear and think of it all the time, then I get just sick of it, nauseated at the thought. Then it comes back as an accept everyday thing. Here's an example of a set of items from the
But... really? That's just a made up story. It seems to match what I think of as a story of popularity. It seems to match a good Hollywood drama: hero has early success and downfall and then third act of redemption.
And it is just the vaguist notion of mood swings. And also what is the point besides entertainment, or schadenfreude or rooting for a comeback?
Look at the following. So sciency. Look at all the data points that you can follow year after year (the data viz is a bit hard to read the course of any particular item, but that's a minor quibble in comparison to the the central problems).
The hype curve might be a useful thing, if only it measured something that is 1) coherent and 2) based on evidence. Introspection is a great inspiration but it is not measurable.
What is the meaning behind the graph? Also whatever the meaning what is the data underlying the graph?
The easy answer is the source of the data. It is simply the 'educated' guess of Gartner analysts. Not an actual number.
Take any particular item. Does it follow the curve? Does it match the icon? Each label is a hype term, but has its own definitional problems. Each term can be vague, have multiple meanings, and have multiple incommensurate sources.
Note also that the shape and timing of the graph is the same for all items. The different point icons are the only appeal to different scales for each item.
So time, the x-axis, is incoherent (unmentioned context based for every item). Different thing might move along the supposed curve at different rates.
But what about the y-axis? Is it popularity, that is, how often an item is mentioned (mentioned in tweets or on google)? or is it how successful an 'item' is (let's say quantitatively, money, earnings per year?) Even these ostensibly measurable concepts are problematic because of definition of terms (is one label the same or different than another).
And once you nail down what the measurement should be, Gartner isn't doing any kind of such measurement, and there's no guarantee that the hype curve shape is a common pattern. It may be that an item's curve is up then down (then dead). Or it may have a steady rise. Or it may have multiple hype peaks at different scales. Or frankly it may have a curve like any stock, up down, steady, with most any pattern imaginable.
If you want to make the hype curve useful. Pick a meaning (or meanings, heck go wild and have many types of hype) and then actually measure it. And only then will people... wel they won't accept that unconditionally, they'll also complain about the coherence of the concept measured and measuring difficulties. But at least it will be scientific evidenced based hype rather than just empty celebrity bullshit hype.
Friday, October 9, 2015
Kalman Filters = dynamic programming on linear systems for sensor accuracy
A Kalman filter is a method to increase the accuracy of a sensor in a linear system. (see this link for a visual explanation and derivation)
The usual example is for the position of a space ship. You have the position/velocity of the ship and also an independent sensor of those. Both of those are somewhat iffy (usually assumed for continuous variables to be Gaussian). Using these two iffy things together, you can get a much more accurate approximation (smaller variance than both) of the current position/velocity.
The other ingredient of the method that makes it get called a Kalman filter is the the change in the sensed data is expected to be linear, so that all of this can be modeled using simple repeated matrix operations.
Of course, this is not limited to dynamic mechanics but it makes the best presentation (because of the linear equations
The point here (which is not to explain Kalman filters) is that the computational method of correction (abstracting away the matrices) is one of a one step recurrence relation (new sensor data at each step too) which is essentially dynamic programming and even better, you only need to know the most recent item.
The usual example is for the position of a space ship. You have the position/velocity of the ship and also an independent sensor of those. Both of those are somewhat iffy (usually assumed for continuous variables to be Gaussian). Using these two iffy things together, you can get a much more accurate approximation (smaller variance than both) of the current position/velocity.
 |
| from bzarg |
The other ingredient of the method that makes it get called a Kalman filter is the the change in the sensed data is expected to be linear, so that all of this can be modeled using simple repeated matrix operations.
Of course, this is not limited to dynamic mechanics but it makes the best presentation (because of the linear equations
The point here (which is not to explain Kalman filters) is that the computational method of correction (abstracting away the matrices) is one of a one step recurrence relation (new sensor data at each step too) which is essentially dynamic programming and even better, you only need to know the most recent item.
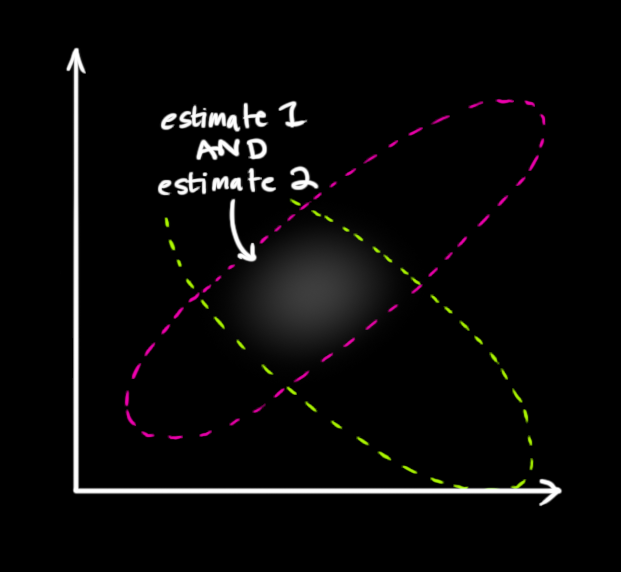
What's the point of a hold-out set?
The purpose of a predictive model is to collect some sample data, calculate some function to help predict future unknown performance, hopefully with low error (or high accuracy).
The classic statistical procedure takes the sample, a small subset of past data called the data or for later purposes the training set, does some rocket science on that set (say, linear regression), produces the model (some coefficients, some small machine that says yes or no or outputs a guess on a single new data point), and maybe also produces some extra measures that says how good or bad the fit is expected to be (correlation coefficient, F-test). And we're done. So many papers and studies have been done over the years that follow this pattern.
But... what is a hold-out set? The modern way (not that modern) is to split the sample randomly into two parts, the training set (on which to do the classic part) and the test set or hold-out set to check. Run the model on all of the items in the test set and see how bad the fit. The test set is distinct from the training set because we want to validate on unseen data, we don't want to assume something we're trying to prove.
Why do this? It seems like such a waste. Why in a sense throw away perfectly good sample data on a test when you could use it in making a more accurate model? Why in a sense test again when you can use that test data to train? More data is better, right?
Well, you're not really throwing it away, but it does seem like a secondary, minor desire. After all, don't most statistical procedures compute some sort of quality measure on the entire set first? This desire not to 'waste' hard won sample data is very understandable; most of the labor in an experiment is not the statistics but in gathering the actual data.
Of course one could weakly justify this test set by saying it gives more reliable quality statistics.
The real desire for a holdout set is to combat overfitting. There are two sides to modeling: real life data is not perfect, the model is trying to get close to the rule behind the data, but it may go too far and get close to the data itself instead of the rule. The classic step gets us the first part, the modern step avoids going too far. A hint to the purpose is another name for the 'hold-out set which is validation set which name gives a better idea of its purpose. You create a model with the training set, and validate it with the validation set. You're validating your model, making sure that it does well what you claim does well. The first step in predictive modeling is to not underfit, to get close to reality that the data hopefully represents. The test or validation step is to make sure you don't overfit, get too close to the data at the expense of reality.
So I've weakly justified the desire for some kind of hold-out/test set. But how does one actually choose this set? Obviously a random subset but what size? The primary issue is a balance between the model and the goodness of fit: with smaller training set, more variance in the model; with smaller test set, more variance in the stats. There's no hard and fast rule (80/20 is considered reasonable).There are a number of strategies to deal with this.
A lot of this ignores the issue of what to do if your validation set has bad performance. What is the statistically 'right thing to do' then? Do you rejigger things knowingly? How adaptive can you be and avoid p-hacking? I'll save that for later.
The classic statistical procedure takes the sample, a small subset of past data called the data or for later purposes the training set, does some rocket science on that set (say, linear regression), produces the model (some coefficients, some small machine that says yes or no or outputs a guess on a single new data point), and maybe also produces some extra measures that says how good or bad the fit is expected to be (correlation coefficient, F-test). And we're done. So many papers and studies have been done over the years that follow this pattern.
But... what is a hold-out set? The modern way (not that modern) is to split the sample randomly into two parts, the training set (on which to do the classic part) and the test set or hold-out set to check. Run the model on all of the items in the test set and see how bad the fit. The test set is distinct from the training set because we want to validate on unseen data, we don't want to assume something we're trying to prove.
Why do this? It seems like such a waste. Why in a sense throw away perfectly good sample data on a test when you could use it in making a more accurate model? Why in a sense test again when you can use that test data to train? More data is better, right?
Well, you're not really throwing it away, but it does seem like a secondary, minor desire. After all, don't most statistical procedures compute some sort of quality measure on the entire set first? This desire not to 'waste' hard won sample data is very understandable; most of the labor in an experiment is not the statistics but in gathering the actual data.
Of course one could weakly justify this test set by saying it gives more reliable quality statistics.
The real desire for a holdout set is to combat overfitting. There are two sides to modeling: real life data is not perfect, the model is trying to get close to the rule behind the data, but it may go too far and get close to the data itself instead of the rule. The classic step gets us the first part, the modern step avoids going too far. A hint to the purpose is another name for the 'hold-out set which is validation set which name gives a better idea of its purpose. You create a model with the training set, and validate it with the validation set. You're validating your model, making sure that it does well what you claim does well. The first step in predictive modeling is to not underfit, to get close to reality that the data hopefully represents. The test or validation step is to make sure you don't overfit, get too close to the data at the expense of reality.
So I've weakly justified the desire for some kind of hold-out/test set. But how does one actually choose this set? Obviously a random subset but what size? The primary issue is a balance between the model and the goodness of fit: with smaller training set, more variance in the model; with smaller test set, more variance in the stats. There's no hard and fast rule (80/20 is considered reasonable).There are a number of strategies to deal with this.
- number not proportion - just make sure you have enough data points in each and after that proportion doesn't matter as much
- resample- do the test a few times on random subsamples. This is the very general procedure bootstrap/jackknife
- data partition and validate each as a test set against the rest - cross validation. This idea is to split the entire dataset into many samples and do the test/training on each set vs the rest. That is, all data is used as part of a training set and all as part of a test set at some point. There are many strategies here: leave one-out (LOOCV), where all but one is the training set and a single item is the test set, but do this for every single item in your data set. Under some models (like general linear regression models) you don't have to repeat the process n times because the math cancels out a lot (linearity is great!). Another method is k-fold CV where you split your data into k pieces (in practice often 5 or 10) and create a model on n-n/k items and validate on the, do that for each of these k pieces. It takes more time (k more times). LOOCV is essentially n-fold CV, so it is not efficient time wise when model creation takes a while (like for SVM)
A lot of this ignores the issue of what to do if your validation set has bad performance. What is the statistically 'right thing to do' then? Do you rejigger things knowingly? How adaptive can you be and avoid p-hacking? I'll save that for later.
Friday, October 2, 2015
Second- and third-order worrying
Once you're able to think consciously, once you're able to name things, you are then able to think about and name those same thoughts, think about thinking. Whether you're conscious of it or not. Consciousness is not necessarily self-awareness but it sure helps.
Some very basic behavioral phenomena could be considered higher order thinking. Altruism, doing something that is not in your immediate (or ever) personal best interest,
Let's say you have anxiety issues, panic attacks brought on by phobias, placed in trigger situations like a door being closed, meeting new people, or something as real life as big dogs. That is a first order anxiety (whether dysfunctional or very useful). A second order anxiety is if you're worried about losing your anxiolytic medication: you're afraid of being afraid.
Another situation: you're clinically depressed, and then you read an article that says that depressed people have a higher chance of contracting disease X (I made this up. I don't know this! Don't worry!). That could be considered grounds for being depressed.
Or paranoia... you could be playing rock paper scissors all day with imaginary adversaries!
So here is the problem. What does higher order worrying do for you?
The moral: Don't worry about third order worrying. After the second turtle (and it's turtles all the way down) they're all pretty much the same kind of turtle.
So that's one thing not to worry about.
Some very basic behavioral phenomena could be considered higher order thinking. Altruism, doing something that is not in your immediate (or ever) personal best interest,
Let's say you have anxiety issues, panic attacks brought on by phobias, placed in trigger situations like a door being closed, meeting new people, or something as real life as big dogs. That is a first order anxiety (whether dysfunctional or very useful). A second order anxiety is if you're worried about losing your anxiolytic medication: you're afraid of being afraid.
Another situation: you're clinically depressed, and then you read an article that says that depressed people have a higher chance of contracting disease X (I made this up. I don't know this! Don't worry!). That could be considered grounds for being depressed.
Or paranoia... you could be playing rock paper scissors all day with imaginary adversaries!
So here is the problem. What does higher order worrying do for you?
- Zero-th order: base activities. Let's say driving a car.
- First order: worrying about those activities. worrying about car wrecks, maintenance, getting lost. All these worries together is what anxiety is. Anxiety is not the next level, it just a set of worries.
- Second order: worrying about worrying too much. Worrying if you have an anxiety problem. I Am I worrying too much? Anxiety about anxiety.
- Third order: worrying about that. Here's the difficulty, what is 'that' and what does worrying about it really mean. Spelled out it is worrying about worrying about worrying. What it means is concerns about whether your concerns about anxiety are a problem. It's not that it is hard to think about (it is hard to think about), but that's not the point. The result though is that it is not an anxiety to have concerns about anxiety, that's not a thing, you just don't do it (also it is not a problem to have concerns over anyway). Your mind just doesn't go there (even after being led there). So it just isn't a concern.
The moral: Don't worry about third order worrying. After the second turtle (and it's turtles all the way down) they're all pretty much the same kind of turtle.
So that's one thing not to worry about.
Subscribe to:
Comments (Atom)